Vous en avez assez de passer des heures à chercher la formulation parfaite pour obtenir de bons résultats avec vos prompts IA ?
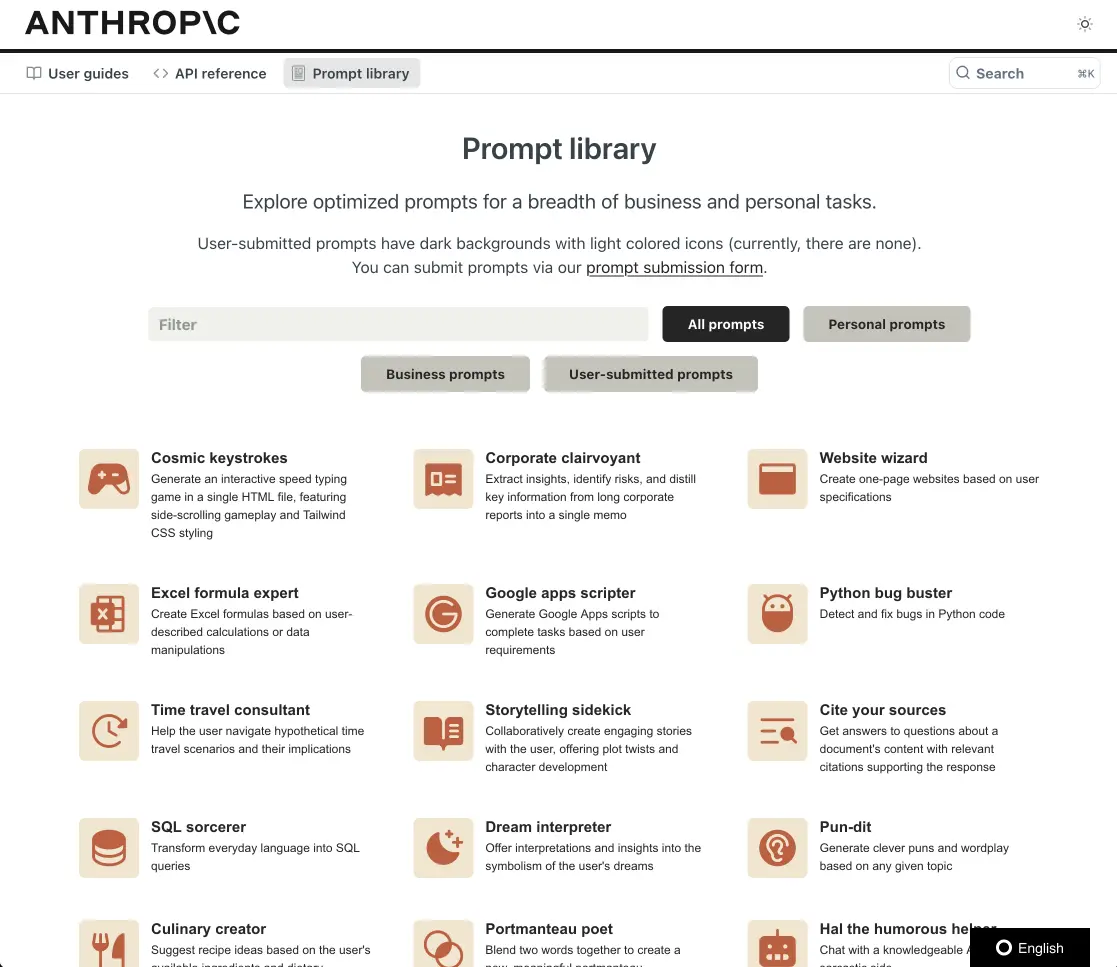
Ne vous cassez plus la tête, puisque Anthropic a pensé à tout avec sa Prompt Library. Cette bibliothèque gratuite de prompts va vous permettre d’interagir plus facilement avec des outils comme Claude3, ChatGPT, Mistral…etc. Les prompts que vous y trouverez sont pré-optimisés pour une multitude de tâches, allant de la rédaction au développement en passant par l’analyse de données. Et ça n’a de cesse de s’enrichir puisque tout le monde peut soumettre ses meilleurs prompts.


Pour l’utiliser, il vous suffit de copier-coller le prompt de votre choix dans votre IA préférée, d’y apporter quelques modifications si le cœur vous en dit, et voilà ! Il y a même le code en TypeScript ou Python qui vous permettra de passer un message « system » avant votre message « user ».

Chacun de ces prompts est le fruit d’un travail minutieux de la part des équipes d’Anthropic dont l’objectif est de fournir des résultats d’e qualité supérieure d’excellente qualité afin de montrer ce que Claude3 a dans le ventre. Et, comme je le disais, il y en a pour tous les goûts… Des prompts pour générer des recettes, interpréter les rêves, se lancer dans la médiation pleine conscience, à des choses plus boulot / business comme créer une marque, rédiger des documents, debugger du code python et j’en passe.
Si ça vous dit de jeter un œil, c’est par ici que ça se passe.